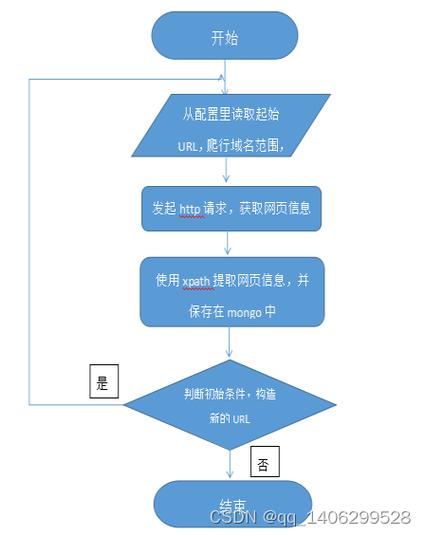
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件 爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与;导语对于一个软件工程开发项目来说,一定是从获取数据开始的不管文本怎么处理,机器学习和数据发掘,都需求数据,除了通过一些途径购买或许下载的专业数据外,常常需求咱们自己着手爬数据,爬虫就显得格外重要,那么Python编程网页爬虫东西集有哪些呢?下面就来给大家一一介绍一下1 Beautiful Soup 客观;网络爬虫web crawler,以前经常称之为网络蜘蛛spider,是按照一定的规则自动浏览万维网并获取信息的机器人程序或脚本,曾经被广泛的应用于互联网搜索引擎使用过互联网和浏览器的人都知道,网页中除了供用户阅读的文字信息之外,还包含一些超链接网络爬虫系统正是通过网页中的超链接信息不断;传统爬虫从一个或多个初始网页的URL开始,抓取并分析这些页面上的链接,不断将新的URL加入队列这个过程会持续进行,直到系统达到一定的停止条件聚焦爬虫的工作流程更为复杂,需要根据网页分析算法筛选与主题无关的链接,留下有用链接并将其加入待抓取的URL队列然后,它会根据搜索策略选择下一步要抓取;一网络爬虫的基本结构及工作流程 一个典型的网络爬虫系统通常包括三个主要部分控制器解析器和资源库控制器负责管理多线程爬虫的工作任务分配,解析器负责下载网页,处理页面内容去除JS脚本标签CSS代码空格HTML标签等,资源库用于存储下载的网页资源,一般采用大型数据库如Oracle存储,并建立;其工作原理一般是从一个或多个初始网页的URL开始,一旦获取这些初始网页,便开始执行抓取过程在抓取网页过程中,爬虫会不断从当前页面中提取新的URL,这些URL随后会被放入队列中等待抓取此过程持续进行,直到达到系统设定的停止条件为止简单来说,网络爬虫就像一只忙碌的蜘蛛,从一个网页开始,顺着链接;Web网络爬虫系统的主要功能是下载网页数据,为搜索引擎提供数据来源许多大型网络搜索引擎都是基于Web数据采集的,这凸显了Web网络爬虫在搜索引擎中的核心地位在网络爬虫的系统框架中,主要包括控制器解析器和资源库三部分控制器负责为多线程中的各个爬虫线程分配工作任务解析器则负责下载网页并进行处;网络爬虫,也被称为网页蜘蛛网络机器人或网页追逐者,是一种自动化工具,它按照预设的规则,在万维网上搜索并抓取信息除了这些常用名称,它还可以被称为蚂蚁自动索引模拟程序或蠕虫根据系统结构和实现技术,网络爬虫可以分为多种类型首先是通用网络爬虫General Purpose Web Crawler,这种爬虫。
HTTrack是一款免费下载工具,适用于多种系统,能完整复制网站结构它不仅易于操作,还支持恢复下载,适合那些需要备份网站的用户7 WebMagic 开源与易学的组合 WebMagic,作为开源Java框架,对新手友好且功能强大,只需少量代码即可实现爬虫模块化设计与多线程支持,使其在爬取动态页面方面表现出色;这是一个很形象的说法,是用来形容象“baiducom,googlecom”等搜索引擎的,在互联网上搜索用户请求的信息象一群虫子一样的的全方位的爬行搜索“爬虫系统”这个词变成了搜索引擎的代名词就是很多虫子,爬;7 PyRailgun一个简单易用的抓取工具,支持抓取javascript渲染的页面,具有高效简洁轻量的网页抓取框架特点简洁轻量高效的网页抓取框架授权协议 MIT以下是部分C++爬虫8 hispider一个快速且高性能的爬虫系统框架,支持多机分布式下载和网站定向下载,仅提供URL提取去重异步DNS。
等待队列所有待抓取的网页URL都会被存储在一个队列中搜索策略爬虫会根据一定的搜索策略从队列中选择下一步要抓取的网页URL网页抓取与重复网页抓取爬虫访问选中的URL,抓取对应的网页内容重复过程上述过程会不断重复,直到满足系统的某一条件时停止网页存储与分析系统存储所有被抓取的。
爬虫软件的质量直接影响了搜索引擎的能力高效的爬虫程序能够更快地收集信息,建立更全面的索引编程结构好算法优化的爬虫软件能够更有效地处理复杂网站结构,提高信息收集的准确性和完整性综上所述,爬虫软件是搜索引擎和其他信息处理领域中的重要工具,它通过自动化地遍历和读取网站内容,为互联网信息;网络爬虫的种类繁多,按照系统结构和实现技术大致可以分为以下几类通用网络爬虫聚焦网络爬虫增量式网络爬虫和深层网络爬虫在实际应用中,网络爬虫系统往往是几种技术的综合应用通用网络爬虫,顾名思义,是一种能够爬取互联网上海量信息的爬虫它能够遍历整个网站,收集网页数据,适用于大规模的数据;5Importio,一款提供从数据爬取到应用完整解决方案的收费网络爬虫工具,广受好评适用于零售制造业数据处理与分析机器学习等领域6HTTrack,免费网络爬虫软件,兼容多种操作系统能将网站内容下载至本地,构建完整目录,支持HTML图像等文件格式,提供更新与断点恢复功能7WebMagic,Java;Web网络爬虫系统的主要功能是下载网页数据,为搜索引擎系统提供数据来源很多大型的网络搜索引擎系统都是基于Web数据采集的,这足以证明Web网络爬虫在搜索引擎中的重要性它不仅能够帮助搜索引擎快速获取最新的网页信息,还能提高搜索结果的准确性和相关性在网络爬虫的系统框架中,主过程由控制器解析器。